Implementing Microservices Architecture: A Practical Guide to Getting It Right
In the fast-paced world of software development, agility, scalability, and speed are no longer optional—they’re essential. Traditional monolithic applications, while simple to begin with, often become difficult to scale and manage as they grow. Enters Microservices: a modern approach to software architecture that breaks applications into small, independently deployable services. But implementing microservices isn’t just about splitting your codebase. It requires a thoughtful strategy, the right tools, and a cultural shift.
This blog explores the core concepts, implementation steps, challenges, and best practices of building applications with a microservices architecture.
What Are Microservices?
Microservices are a design approach in which a single application is composed of many small services, each running in its own process and communicating using lightweight protocols (usually HTTP or messaging queues). Each service focuses on a specific business function and can be deployed, scaled, and updated independently.
Key Characteristics:
- Loosely coupled
- Independently deployable
- Organized around business capabilities
- Decentralized data management
Unlike monoliths, where all components are interdependent and deployed as a single unit, microservices enable faster development cycles and better scalability.
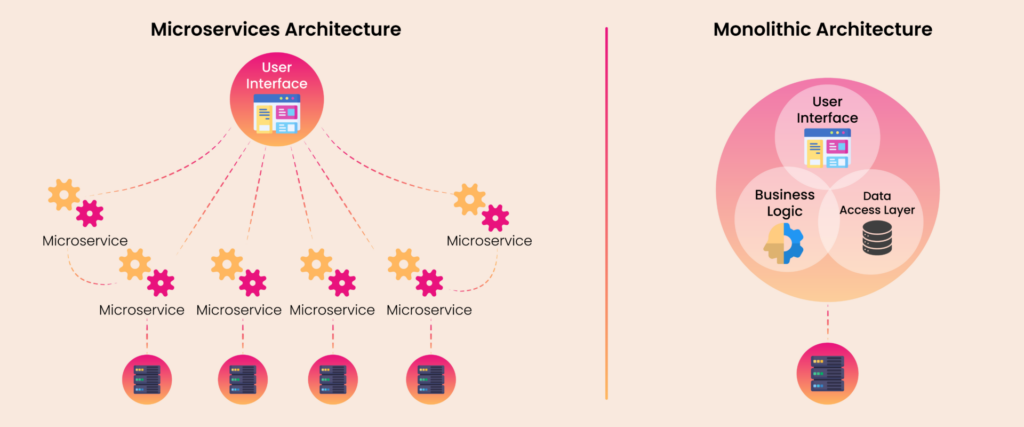
When Should You Consider Microservices?
Microservices aren’t a silver bullet. They’re ideal when:
- Your monolith is becoming unmanageable.
- You need to scale components independently (e.g., cart vs. payment).
- Different teams work on different modules and need independence.
- You’re adopting DevOps or CI/CD pipelines.
Core Steps to Implement Microservices
1. Define Service Boundaries
Use Domain-Driven Design (DDD) to identify bounded contexts. Each microservice should handle one specific business domain (e.g., user management, order processing, payment processing).

2. Choose the Right Tech Stack
Microservices give you the freedom to use different languages and frameworks, but be cautious—it can add complexity. Popular choices:
- Languages: Java (Spring Boot), Node.js, Go, Python
- Containers: Dockers
- Orchestration: Kubernetes
- Communication: REST, gRPC, Kafka, RabbitMQ
3. Manage Data Carefully
Each service should own its own data. Avoid shared databases. Patterns:
- Database-per-service
- Event sourcing
- CQRS (Command Query Responsibility Segregation)

4. DevOps and CI/CD
Automation is key. Set up pipelines to build, test, and deploy services independently. Tools to consider:
- GitHub Actions, GitLab CI/CD
- Jenkins
- Docker Hub
5. Monitoring
A distributed system without monitoring is a nightmare. Implement:
- Centralized Logging: ELK Stack (Elasticsearch, Logstash, Kibana, Splunk)
- Monitoring: Prometheus + Grafana
- Tracing: Jaeger, Zipkin, OpenTelemetry

Challenges in Microservice Implementation
- Increased Complexity: More services = more moving parts. You'll need orchestration, service discovery, and network-level resilience.
- Data Consistency Distributed transactions are hard. You'll need to rely on patterns like saga or eventual consistency.
- Latency and Network Failures Services talk over the network, introducing latency and potential points of failure.
- Team Coordination A microservices culture demands cross-functional teams and clear ownership.
Best Practices for Microservices
- Start Small: Migrate one business function at a time.
- Use API Gateways: Tools like Kong or AWS API Gateway can help with authentication, rate limiting, and routing.
- Smart Endpoints: Keep your business logic in the services, and make the communication layer thin.
- Build for Failure: Implement retries, timeouts, and circuit breakers (Netflix Hystrix or Resilience4j).
- Automate Everything: CI/CD, testing, and monitoring should be part of the foundation.
Case Study: Order Ingestion Application
Problem Statement:
The current Sales/Return imports to OMS are point-to-point integrations that use heterogeneous technology stacks. There are varying platforms that generate orders/returns with reliance on a shared instance of IBM Sterling for OMS needs across North America, APAC, and EMEA regions.
- Regional autonomyis needed for sales/return data inputs to OMS.
- Ability to deploy changes based on regional needs.
- Ability to modify or change hotfixes based on regional needs.
- Reduced blast radius against regional changes to business logic processing sales/return data.
- Architecture and solution should also support regional needs as well as global needs while maximizing the stability of the OMS.
Solution Implemented:
- Guests/Store Educators place orders through sales/return tracking channels (e.g., SFCC, BBR, OSB, Narvar, etc.)
- Order Import Apps, specific to channels or geographic regions, extract and encrypt the full Sales/Return payload before posting it to the “Order Data” Topic.
- Channel/Geo-specific Translation Apps convert Sales/Return payload to OMS Order Topic.
- Channel/Geo-specific Order Ingestion Apps filter, transform the canonical Order Payload to IBM Sterling format with IBM Sterling defaulting, and invoke IBM Sterling API via proxy to create orders with the relevant Order (Sales/Return) payload.
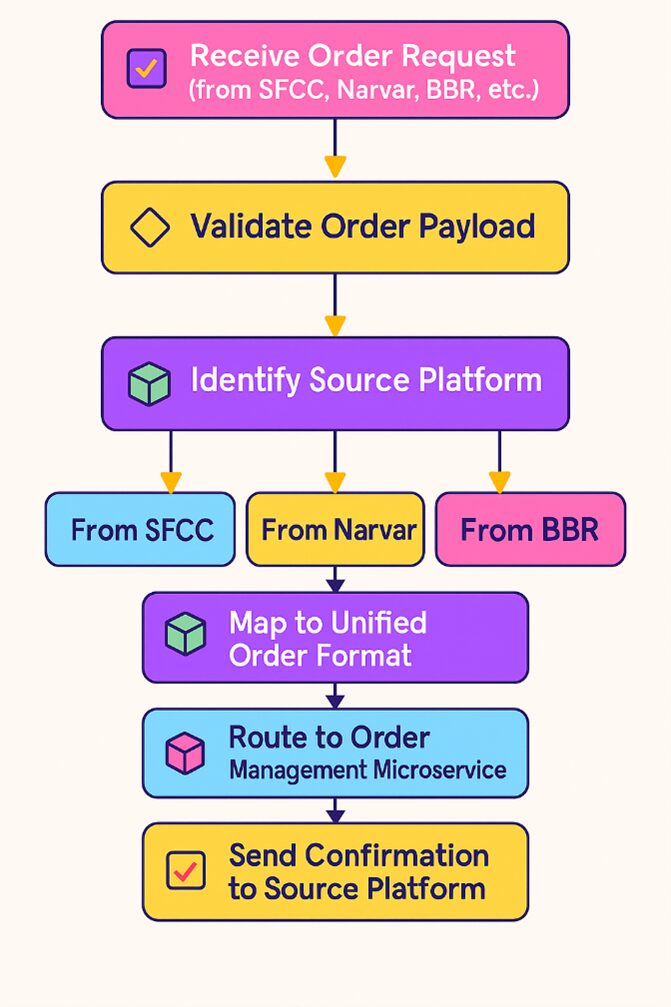
Result :
- Deployment frequency increased by 5x.
- Faster time to market since less cross-channel dependency.
- Provide the ability to onboard business capabilities faster in the future
- System downtime has been reduced significantly.
- Remove dependency on the Integration layer.
- Reduce dependency on IBM Sterling.
Author Details

Geetha S
Associate Architect
Geetha HS is an Associate Technical Architect at Perfaware, bringing over 13 years of expertise in solution design, integration, and product consulting. She has played a key role in IBM Sterling OMS implementation and customization for major retail projects in the US and UK.